Case Study: How OpenRussian lets students contribute to their database
OpenRussian is the world’s leading Russian dictionary for English- and German-speaking learners. If you’e learning Russian, try OpenRussian to look up words and learn with flash cards!
Their concept is similar to Wikipedia: every visitor can participate and contribute missing words or expressions, fill in incomplete data or correct faulty translations or word inflections.
Operation and challenges
Allowing user contributions means that participants have a lot of functionality in the website’s interface that is typically found in admin panels — such as editing a word’s translation or changing its “related entries“. In addition to user contributions, a small team of students at OpenRussian also correct and expand the dictionary data, working directly on the website in the same way the users do. This high degree of coordination is made possible by the website’s interface, which allows in-place data adjustments.
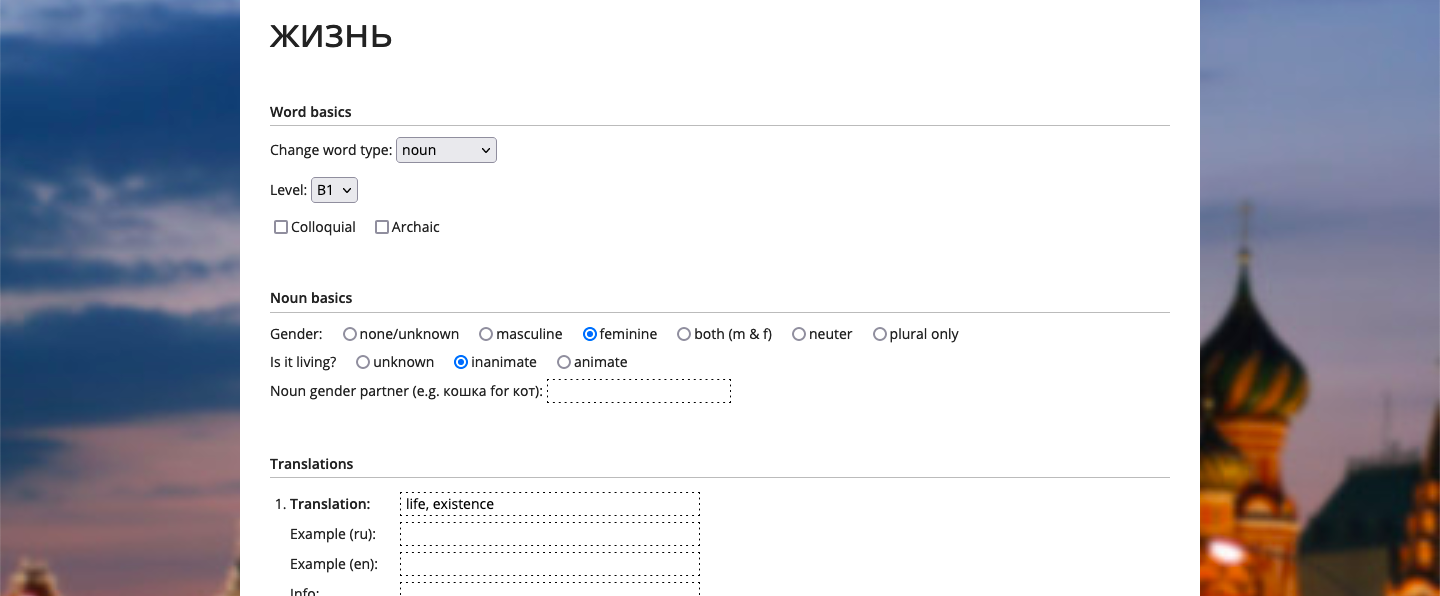
This division of labor covers most data editing use cases but more complex changes required the founder to regularly and directly access the database to fix the data. Setting up database access and requiring all staff to learn a database access tool was too bothersome, so the process was never undertaken.
Adoption of TogetherDB
To offload the founder’s work on the database to the students, they wanted to try TogetherDB. So, they registered on togetherdb.com and created a company account in just one minute.
To connect TogetherDB to their MySQL database, the OpenRussian founder navigated to their Amazon AWS interface and opened the firewall for the database server so that the German worker server could connect to it from its specific IP address. Following the manual, they created the database user, and then in TogetherDB created the new connection with those details. Now in the dashboard, the founder can see the database connection and click it to browse the database with all its tables and data.
The second step was setting up the company’s accounts. In the settings, the founder added all three students to the company via their email addresses, and the students then received an email with a link to join. He then created the group “Students“ to which he added all three of them.
Last but not least they set up the sharing configuration for the database. The kicker here was the fine granular permissions so the students can only change data in specific columns and not inadvertently break anything.
The sharing configuration was:
- Shared to: Group “Students“
- Base access: Read access
- Exceptions: Can write in certain columns, e.g. can change the values in column “disabled“ of table “sentences“
- Can execute SQL: No
The aftermath
With four seats in the company’s account, they chose the “Starter“ plan for just $41 per month. For that their founder saves a few hours every single week needing to look into the database and making corrections himself — he’s now enabled his students to do that for him. The only other alternative would have been to develop a custom admin interface, but this would be a lot of work and would require frequent adjustments when the database structure changes.
The students could immediately use the new database interface without training. The founder now has extra time to invest into more fruitful tasks to advance the company.
And another use: Publishing data
Since the OpenRussian website’s inception, the team has published their entire dictionary database as a way to give back to the community. The idea is that other dictionaries can use the data too so the users’ contributions have an even wider impact. They used to create weekly CSV file exports, automated by a cronjob, which then got uploaded to a public GitHub repository by hand.
While this was not too tedious, they now also use TogetherDB to publicly share the full database. This was done with a simple sharing configuration in the interface, sharing to the public with “read” access. This gives anybody with the link the ability to download each table as a CSV file with fresh and up-to-date data. The GitHub repository where the data was previously hosted now just contains the link to this database — and the cronjob and manual uploads are obsolete!